


Trusted Knowledge Exploration



ICLR 2024(Spotlight)
Xuming Hu, Junzhe Chen, Xiaochuan Li, Yufei Guo, Lijie Wen, Philip S. Yu, Zhijiang Guo
Pinocchio is a benchmark assessing large language models' (LLMs) factual knowledge across diverse domains and languages, through 20K questions. It reveals LLMs' limitations in handling factual information and spurious correlations, emphasizing challenges in achieving trustworthy artificial intelligence.ICLR 2024
Aiwei Liu, Leyi Pan, Xuming Hu, Shu’ang Li, Lijie Wen, Irwin King, Philip S. Yu
Recent advancements in text watermarking for LLMs aim to mitigate issues like fake news and copyright infringement. Traditional watermark detection methods, reliant on a secret key, are vulnerable to security risks. To overcome this, a new unforgeable watermark algorithm has been developed, employing separate neural networks for watermark generation and detection, while sharing token embedding parameters for efficiency.ICLR 2024
Aiwei Liu, Leyi Pan, Xuming Hu, Shiao Meng, Lijie Wen
To address the security and counterfeiting issues in current text watermarking for LLMs, we employs distinct neural networks for watermark generation and detection, sharing token embedding parameters for efficiency. This approach ensures high detection accuracy and complicates forgery attempts, offering enhanced security and computational efficiency with fewer parameters.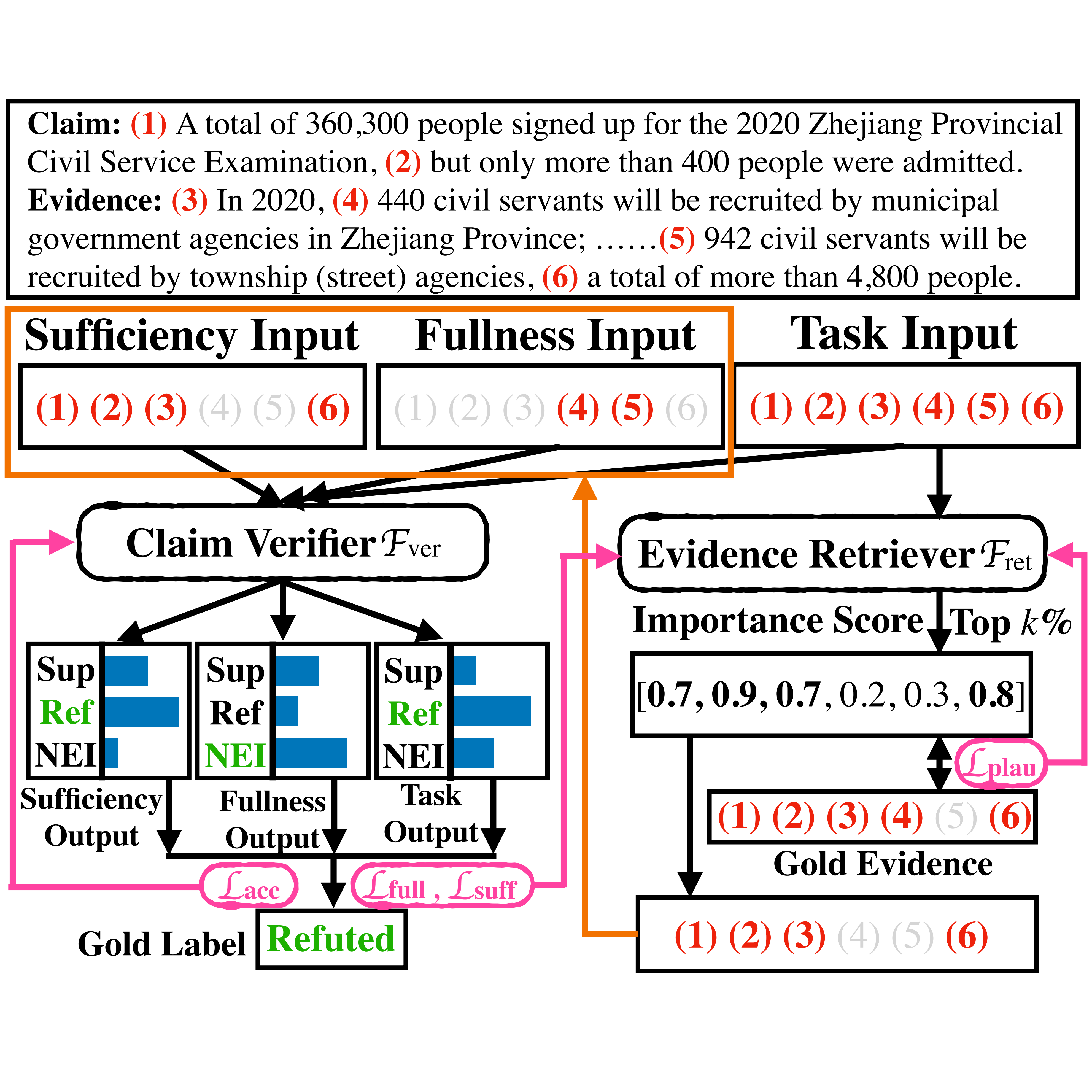

SIGIR 2023
Xuming Hu, Zhaochen Hong, Zhijiang Guo, Lijie Wen, Philip S. Yu
ReRead is a fact verification model designed to enhance the accuracy of real-world fact verification tasks. It retrieves evidence from source documents, focusing on obtaining evidence that is both faithful (reflecting the model's decision-making process) and plausible (convincing to humans).SIGIR 2023
Xuming Hu, Zhijiang Guo, Junzhe Chen, Lijie Wen, Philip S. Yu
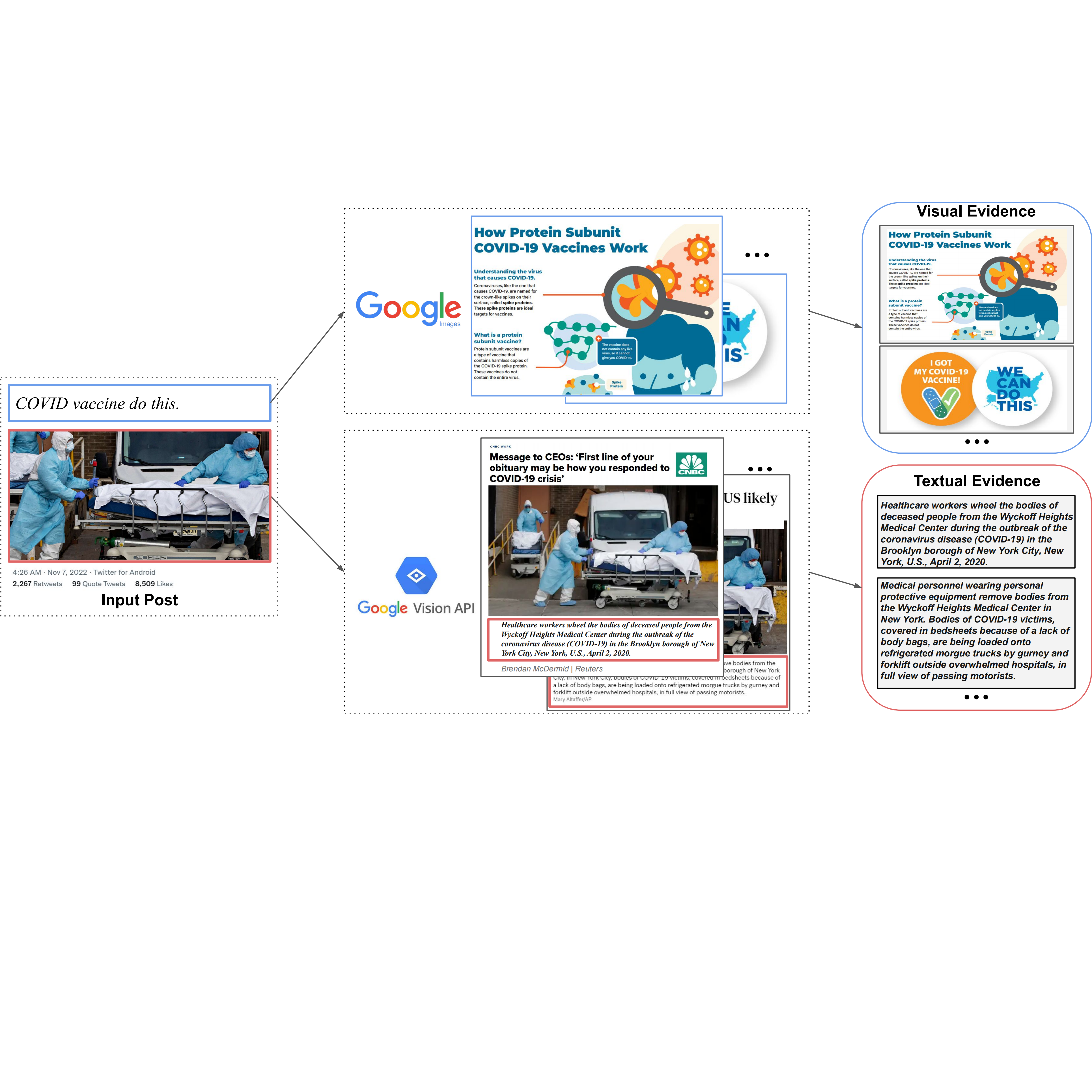
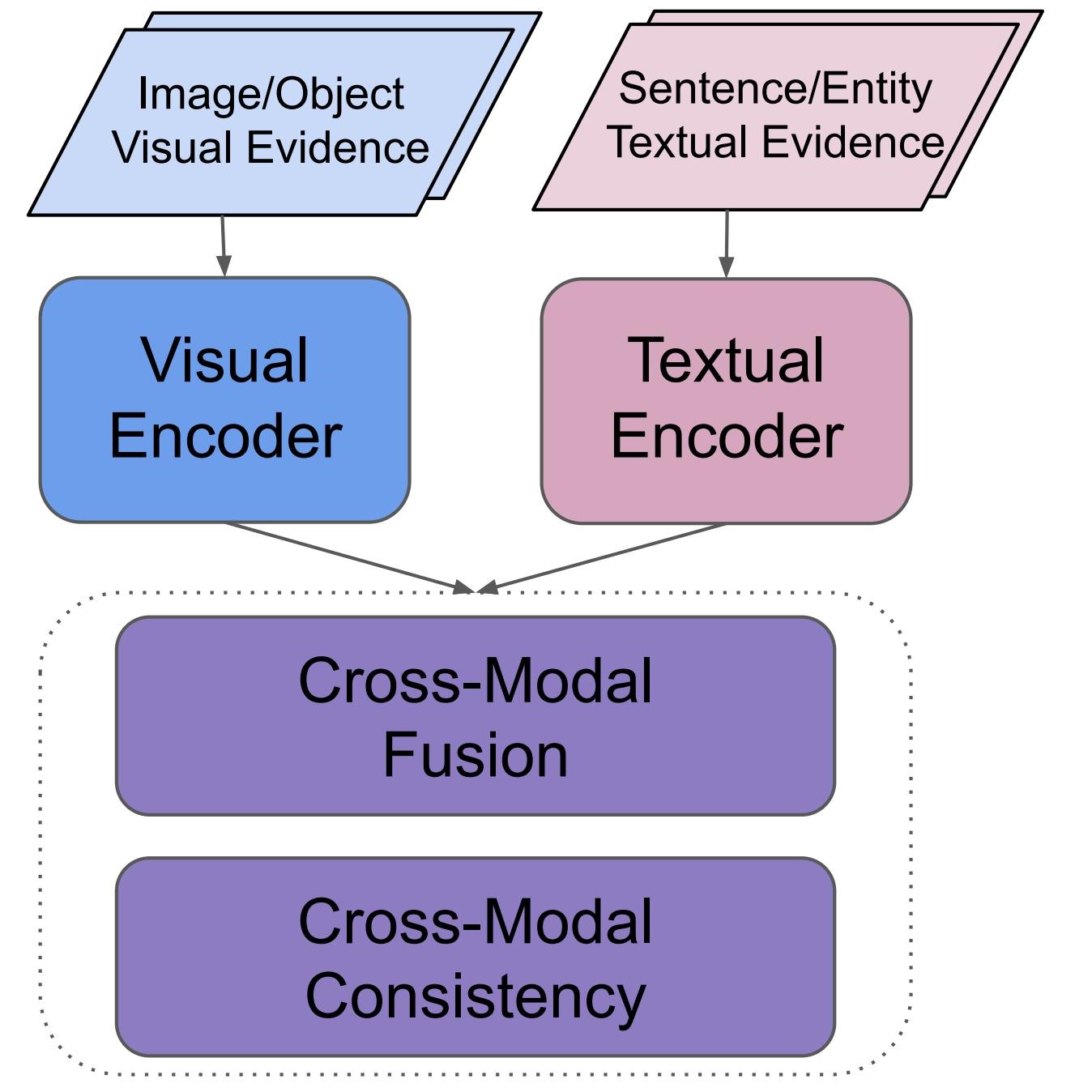
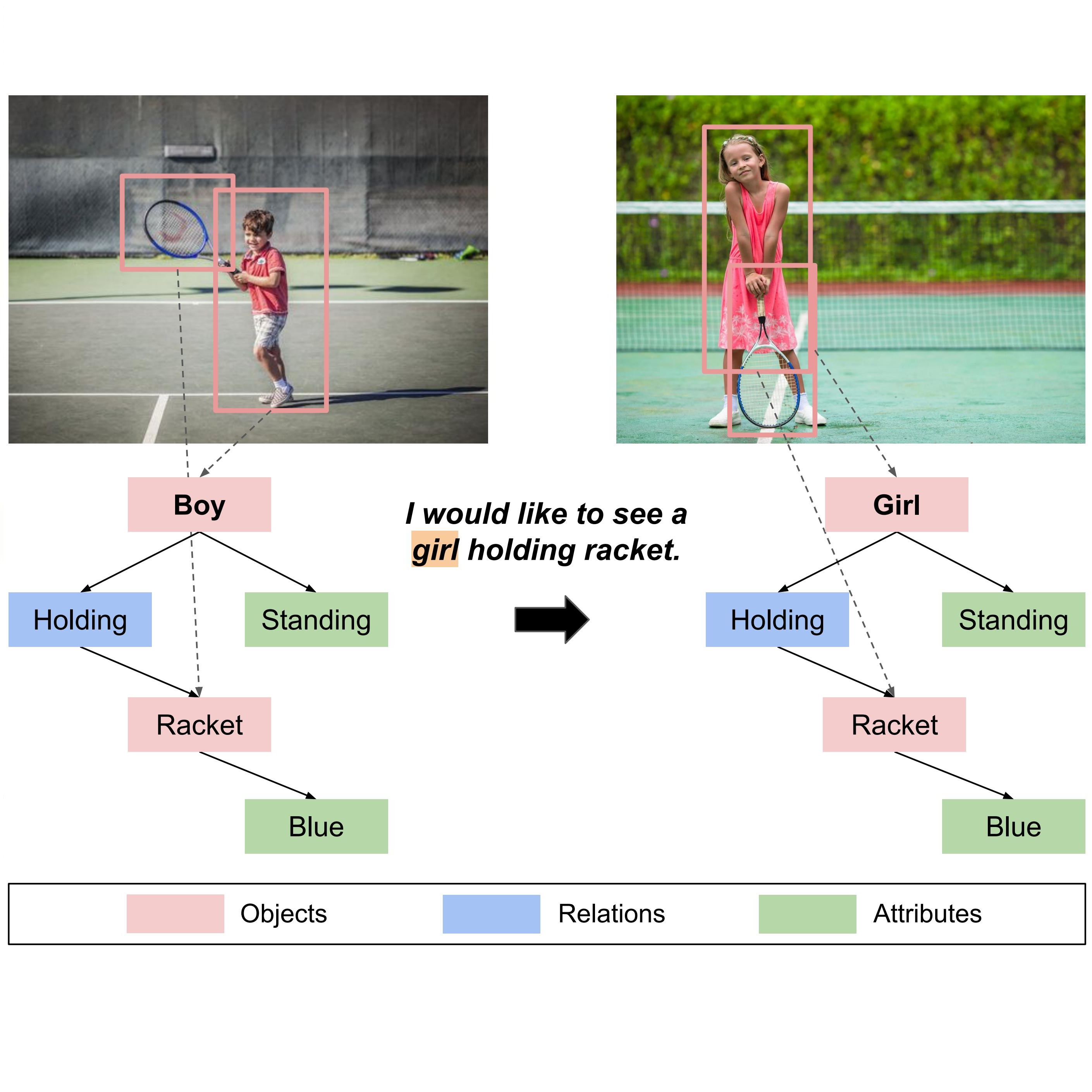
MR2 is a multimodal, multilingual dataset for rumor detection, addressing the evolving nature of misinformation on social media, which increasingly intertwines text and images. It offers a platform for developing advanced rumor detection systems capable of retrieving and reasoning over internet-sourced evidence from both text and image modalities. This dataset provides a challenging testbed for evaluating such systems.NAACL 2022
Xuming Hu, Zhijiang Guo, Guanyu Wu, Aiwei Liu, Lijie Wen, Philip S. Yu
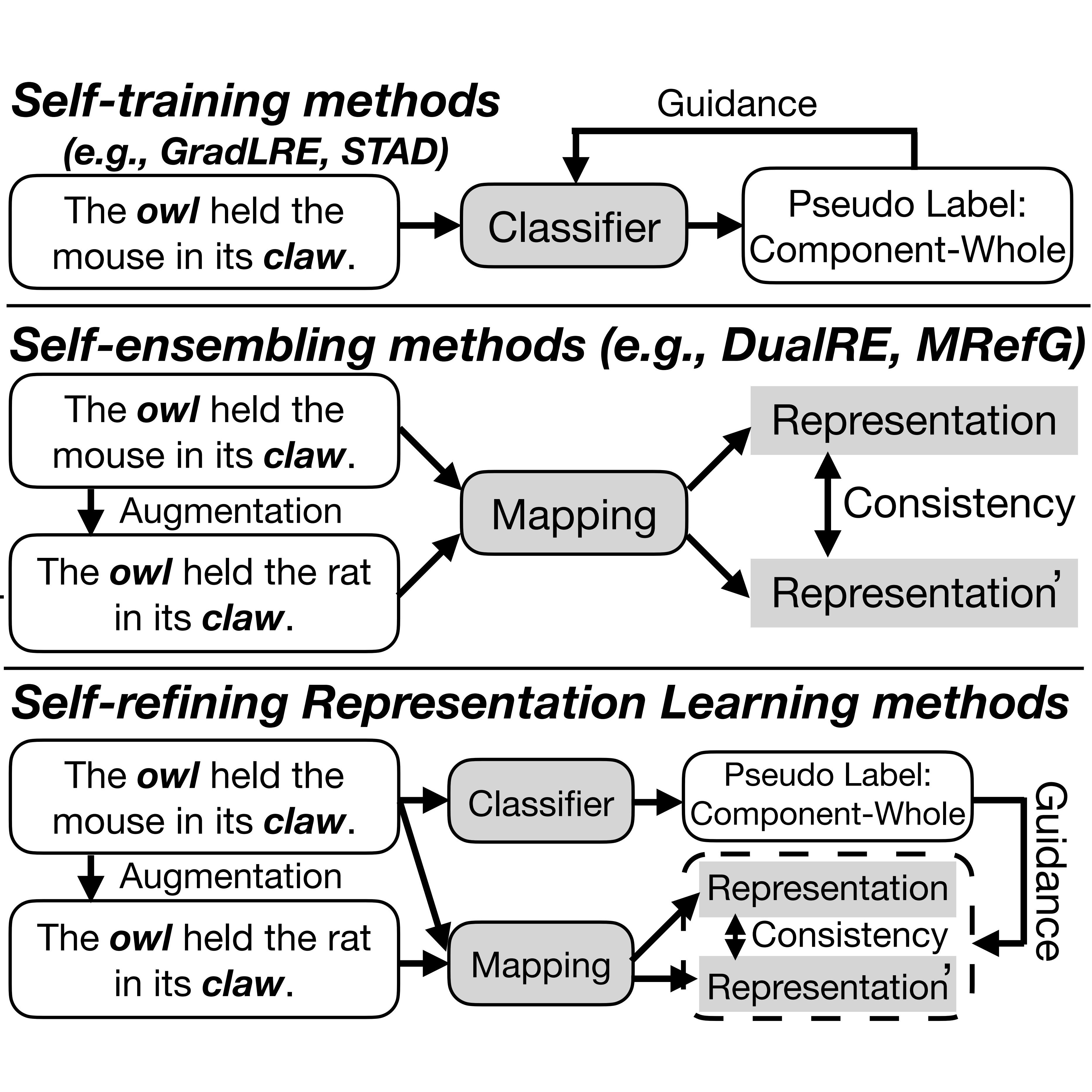
CHEF is the first Chinese Evidence-based Fact-checking dataset, featuring 10K real-world claims across various domains like politics and public health, with annotated evidence from the Internet. It aims to address the scarcity of non-English tools in automated fact-checking, particularly for Chinese.


{kind=link}